Návod ke KonTextu
KonText je webové rozhraní ke korpusovému manažeru Manatee. Na Vokabuláři webovém zpřístupňuje KonText původní staročeskou (STB) i středněčeskou textovou banku (SDTB).
Obsah
- O KonTextu
- Základní pojmy
- Uživatelský účet
- Zadání jednoduchého vyhledávacího dotazu
- Zobrazení vyhledaných výsledků
- Úprava zobrazení konkordance
- Výběr prohledávaných textů
- Frekvenční seznam
- Ruční třídění řádků
- Hledání v anotaci slovních tvarů
- Dostupná anotace korpusů
- Ukázkové dotazy
O KonTextu 🔗
KonText je vyvíjen v Ústavu Českého národního korpusu, Manatee (součást Sketch Engine) v otevřené verzi poskytuje společnost Lexical Computing.
Podrobný návod ke KonTextu je dostupný na stránkách ČNK. Naleznete tam i 7dílný úvodní kurz, který se posléze věnuje i zvláštnostem hledání v tamějším diachronním korpusu Diakorp.
Základní pojmy 🔗
Rovněž se tam můžete seznámit s některými pojmy z korpusové lingvistiky, které jsou použité i v tomto návodu. Za významově/referenčně blízké až (s jistým zjednodušením) zaměnitelné můžete považovat termíny token, pozice, (slovní) tvar a textové slovo.
Pojem (korpusová) anotace zahrnuje lemmatizaci a morfologické značkování, což je dodatečná informace na úrovni tokenů/pozic připojovaná k nim formou pozičních atributů(1), a také zahrnuje metainformace/metadata uložená jako strukturní atributy na úrovni celých textových pramenů/dokumentů i menších segmentů/struktur (tj. např. kapitol, veršů, vět).
(1) Např. neprázdné poziční atributy tokenu snieh
(viz část Dostupná anotace korpusů)
v Klaretově Bohemáři jsou samo textové slovo snieh
(atribut word), jeho pomocná podoba malými písmeny snieh
(lc, lower case), možná lemmata
snieh|sníh|sněh, (možné) hyperlemma snieh,
morfologické značky (tag a atag) a
transliterace (podoby v textovém prameni) snyeh.
Uživatelský účet 🔗
Některé funkce popsané v tomto návodu jsou dostupné pouze po
přihlášení. K získání vlastního uživatelského účtu je třeba
vyplnit a odeslat registrační formulář, jenž se zobrazí po kliknutí
na odkaz Zaregistrovat se v záhlaví KonTextu,
a dokončit registraci kliknutím na odkaz v potvrzovací zprávě,
kterou KonText pošle e-mailem z adresy
ridics-noreply@ujc.cas.cz (takto ji poznáte, pokud ji
vyřadí spamový filtr).
Zadání jednoduchého vyhledávacího dotazu 🔗
Po otevření aplikace KonText se dostanete na formulář pro zadání vyhledávacího dotazu. Mezi korpusy si vyberte v nabídce vedle popisku Korpus kliknutím na název momentálně zvoleného korpusu (např. Staročeská textová banka 1.1.10.1, která obsahuje texty mezi lety 1300–1500). K dispozici je ještě středněčeská (1500–1800) a staro- a středněčeská (1300–1800) textová banka, jež vznikla spojením prvních dvou.
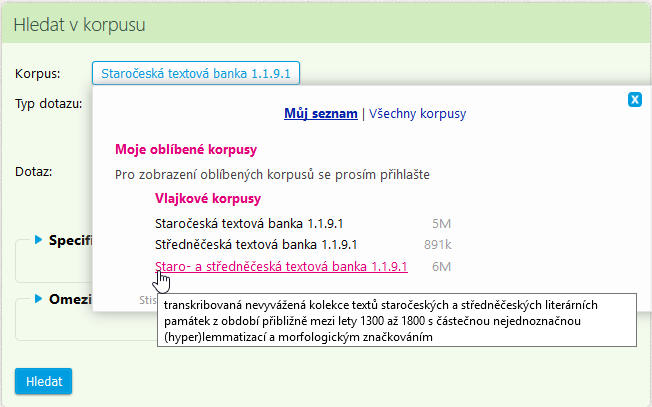
Chcete-li vyhledat v textové bance konkrétní doklad (např. sněhem), zapište požadovaný tvar do políčka Dotaz a potvrďte tlačítkem Hledat (nebo klávesou Enter ⏎). Takto můžete vyhledat i slovní spojení (např. v sněhu).
Výchozí typ dotazu Základní nehledá pouze zadaný slovní tvar nebo slovní spojení, ale zároveň výrazy v dotazu interpretuje i jako základní tvary (lemmata). Proto dotaz snieh vyhledá i všechny tvary tohoto lemmatu. Tomuto chování se vyhnete zvolením typu dotazu Fráze.
Tento typ dotazu (resp. všechny kromě typu Základní) navíc umožňuje
hledat slovní tvary nebo spojení s využitím
regulárních
výrazů. Ukázkový dotaz
sn(ie|í|ě)[hz].* (příklad můžete zkopírovat
tlačítkem a vyhledat odkazem
🔗)
vyhledá všechny (i nástupnické) tvary lemmatu snieh, ale i
několik nesouvisejících. Hledat můžete rovněž v korpusové anotaci,
která zahrnuje už zmíněnou lemmatizaci.
![vyhledávací dotaz sn(ie|í|ě)[hz].*](dotaz_sniehz.png)
Krátký popis typu dotazu se zobrazí kliknutím na ikonku s otazníkem
( ). Srovnání typů dotazů naleznete
v manuálu
ke KonTextu (formou tabulky) a v úvodním
kurzu (formou prózy i tabulky).
). Srovnání typů dotazů naleznete
v manuálu
ke KonTextu (formou tabulky) a v úvodním
kurzu (formou prózy i tabulky).
Zobrazení vyhledaných výsledků 🔗
Výsledkem hledání jsou konkordanční řádky se záhlavím nalevo (ohraničeno červeně), hledaným výrazem uprostřed (key word in context, KWIC, rovněž červeně) a levým a pravým kontextem. V záhlaví se uvádí zkratka pramene a číslo folia.
Pro ilustraci pojmů: (meta)informace v záhlaví pocházejí
z atributů struktur pro pramen a folio. U pozice uprostřed
se zobrazují až tři poziční atributy (word, hyperlemma
a emendace), čtvtý, který naznačuje přítomnost lomítka
(a nejspíš jde o atribut transliterace), je prázdný.
![výsledky vyhledávacího dotazu sn(ie|í|ě)[hz].*](konkordance_sniehz.png)
Širší kontext si zobrazíte kliknutím na hledaný výraz.
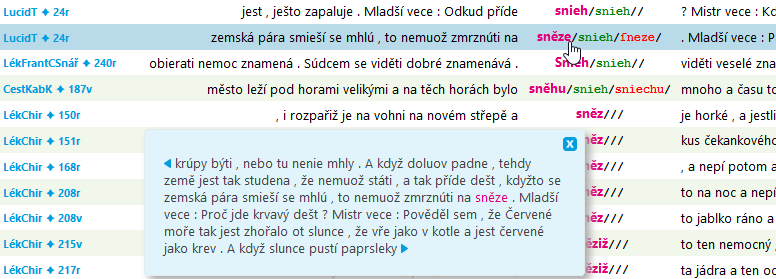
Po kliknutí na záhlaví konkordančního řádku se dostanete k dodatečným informacím o dané pozici, především strukturním atributům. Kromě údajů o dokumentu a foliu jsou v tabulce odkazy do Vokabuláře webového: na ediční poznámku, folio digitální edice v edičním modulu a hledání ve staročeských slovnících (zatím pouze u výrazů, které mají přiřazeno hyperlemma, viz část Dostupná anotace korpusů).
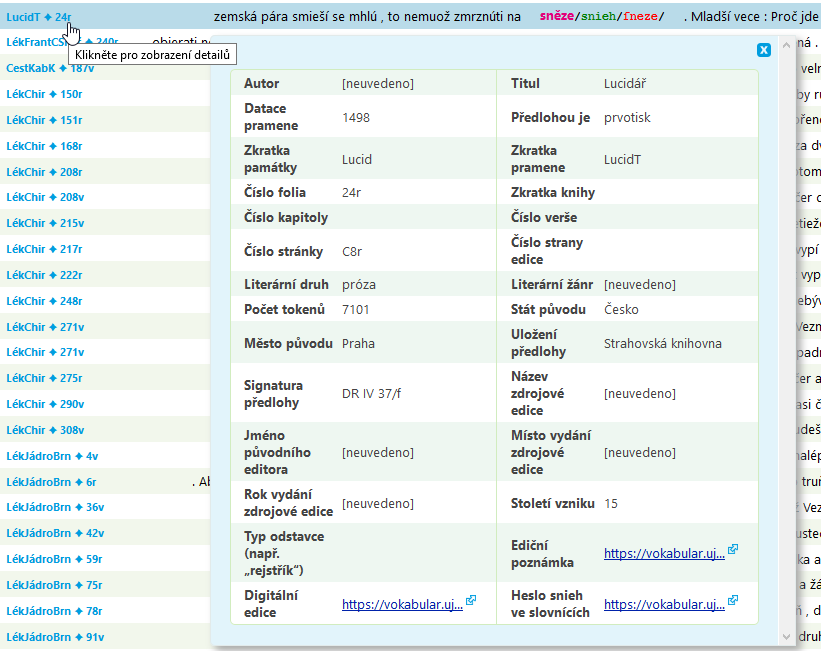
Výsledky hledání v korpusu (nejen konkordance) uložíte prostřednictvím nabídky Uložit. Funkce v nabídce popisuje manuál a podrobnější informace naleznete v úvodním kurzu.
Úprava zobrazení konkordance 🔗
Prostřednictvím nabídky Zobrazení lze ovlivnit počet zobrazených řádků s výsledky, šířku kontextu a zvolit dodatečné informace.
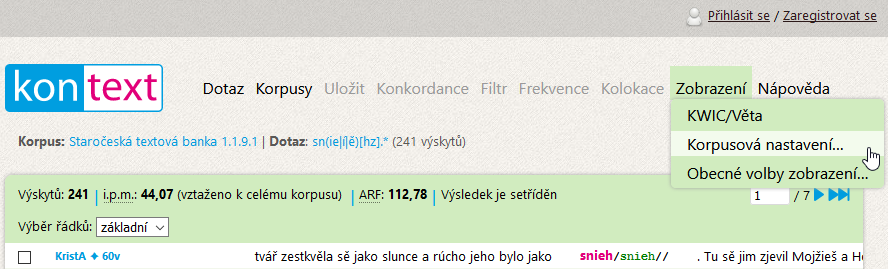
Dialog Obecné volby zobrazení slouží např. k nastavení těchto voleb (v obrázku ohraničených červeně): počtu konkordančních řádků na jedné stránce a počtu tokenů (textových slov, pozic) v levém a pravém kontextu vyhledaného výrazu (KWIC).
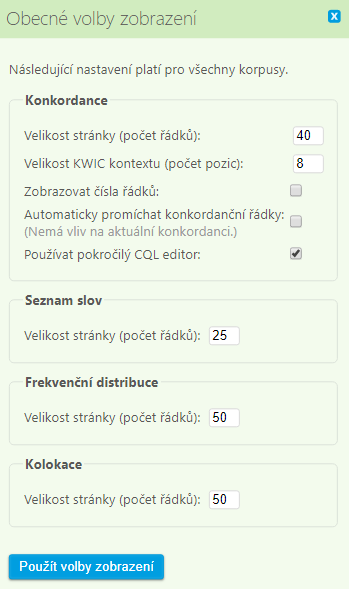
V dialogu Korpusová nastavení (jenž se otevírá z nabídky Zobrazení > Korpusová nastavení…) si můžete vybrat, které z rovin korpusové anotace se mají zobrazovat v konkordančních řádcích (viz sloupce Poziční atributy a Struktury [a jejich atributy] v obrázku níže) i jejich záhlavích (sloupec Metainformace, v němž jsou rovněž strukturní atributy).
Aby se poziční atributy zobrazily přímo v konkordančním řádku (a ne pouze v bublině po najetí myší, viz druhý obrázek níže s hyperlemmatem sstupovati), je třeba nastavit volbu Jak zobrazovat další poziční atributy? na druhou hodnotu v textu pro KWIC (v obrázku je ohraničena červeně a je nad ní kurzor).
V ukázkách výše se u KWIC zobrazovaly
- zelenou barvou slovníkové tvary (hyperlemmata),
- modrou barvou transliterace zápisu v prameni a
- červenou transliterace chybného původního zápisu (při emendaci).
Další momentálně používané (provizorní) barvy pozičních atributů jsou
-
(opět) červená
pro
lemmaa -
modrá
pro atribut
hlt–hyperlemma_tag(spojení hyperlemmatu a poziční morfologické značky pomocí podtržítka).
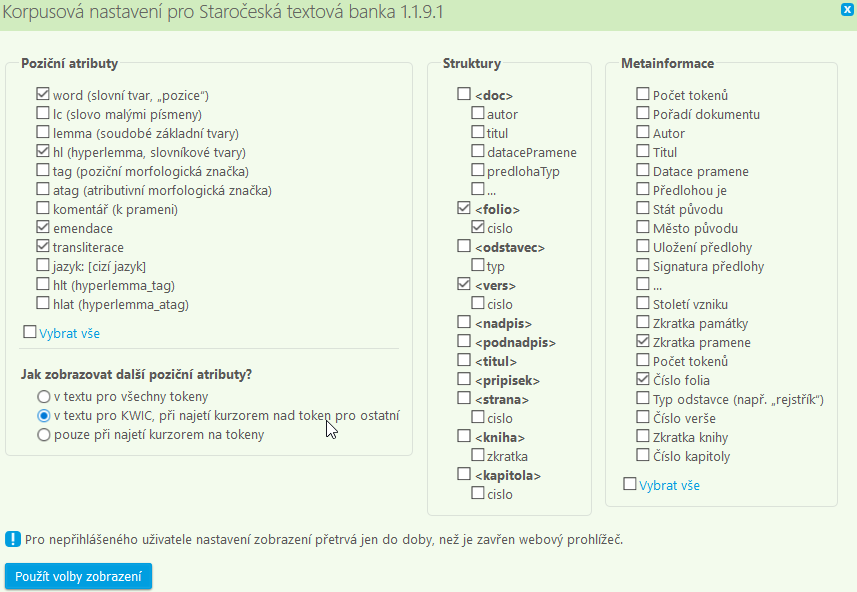
V konkordančních řádcích lze rovněž povolit (ve sloupci Struktury) zobrazení hranic např. veršů nebo folií, volitelně i s číslem verše nebo folia.
Pro ilustraci pojmů: Červeně ohraničen je celý verš (korpusová struktura) a vpravo od něj se zobrazuje začátek folia s číslem (strukturní atribut).

Vybrané položky ze sloupce Metainformace se zobrazují (v pevném pořadí) modrou barvou v záhlavích konkordančních řádků.
Výběr prohledávaných textů 🔗
Ve formuláři pro zadání vyhledávacího dotazu je možné hledání omezit na konkrétní texty (podle zkratky názvu literární památky nebo jejího pramene), případně jejich části – např. biblické knihy, kapitoly, folia, verše.
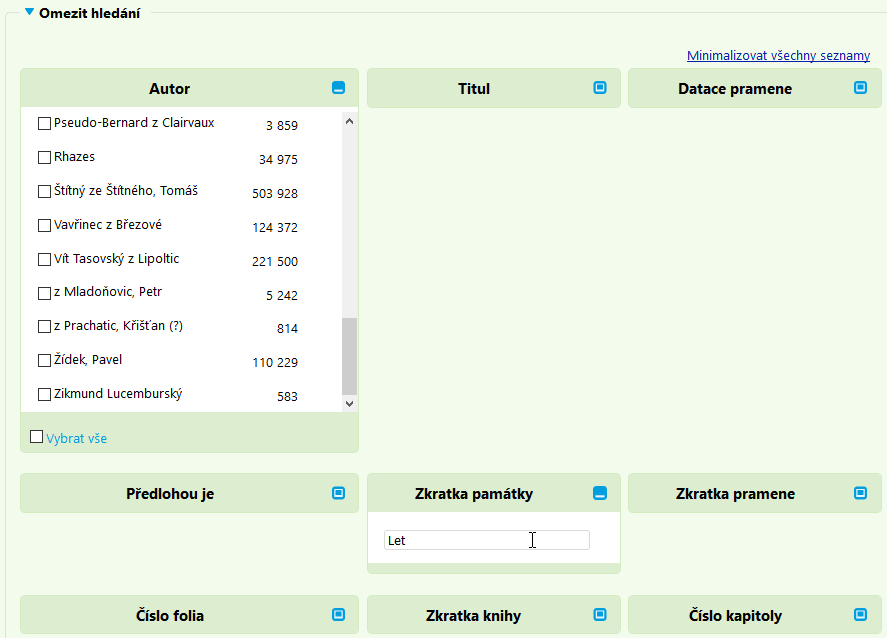
V ukázce níže vidíte dva způsoby výběru textů: označením ve
výčtu (v případě autora textu) a přímým zadáním zkratky
(Let pro Staré letopisy české; výčet se
nenabízí kvůli množství položek, použít můžete přehled
textů začleněných do textových bank).
Prohledávané texty můžete vybrat dále např. podle autora,
žánru/tématu (lékařství) a datace pramene.
Dalším způsobem, jak omezit hledání na vybrané texty, je pomocí pojmenovaných subkorpusů. Zaregistrovaní uživatelé mohou prostřednictvím nabídky Korpus vytvářet a používat vlastní subkorpusy. V kurzu práce s KonTextem jsou popsány dva způsoby, jak subkorpus vytvořit.
Vytvořené subkorpusy jsou pak vázané na původní korpus. Ve formuláři pro zadání dotazu lze vybírat mezi hledáním v celém zdrojovém korpusu, anebo v některém z jeho subkorpusů.
Frekvenční seznam 🔗
Užitečným pomocníkem se může stát frekvenční seznam vytvořený z jedinečných tvarů v aktuální konkordanci. V nabídce Frekvence naleznete zejména tvorbu seznamu hyperlemmat, slovních tvarů (bez ohledu na velikost písmen) a podle vlastního nastavení, které umožňuje vytvářet frekvenční seznamy (i několika) pozičních i strukturních atributů (chcete-li zjistit všechny jejich hodnoty), a to nejen vyhledaného výrazu, ale i sousedních pozic. Umožňuje rovněž určit minimální frekvenci a ovlivnit další možnosti.
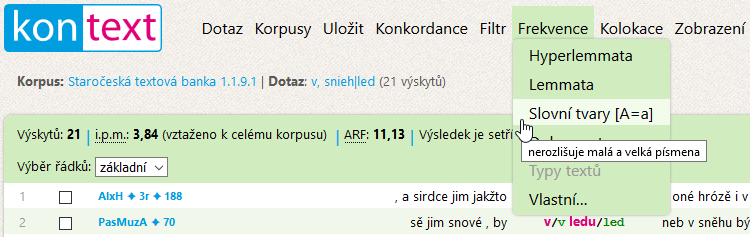
Místo procházení 21 (nebo podstatně většího množství) konkordančních řádků může být rychlejší se nejdříve zorientovat ve 4 řádcích frekvenčního seznamu slovních tvarů. Seznam lze řadit podle frekvence i abecedně (kliknutím na podtržené záhlaví sloupce).
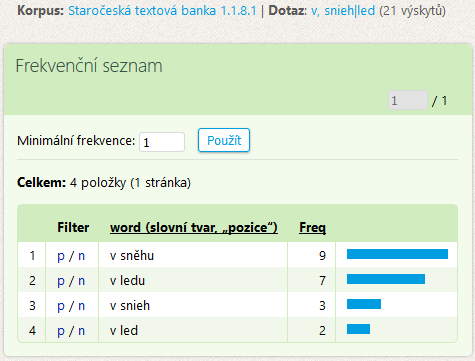
Ve sloupci Filter naleznete dva odkazy. První z nich – p(pozitivní) – vybere z aktuální konkordance pouze řádky s danými slovními tvary (např. v sněhu). Druhý z nich – n(egativní) – z konkordance řádky s těmito tvary odstraní.
Bohatší popis vytváření frekvenčního seznamu naleznete v manuálu ČNK.
Ruční třídění řádků 🔗
Není-li nalezených konkordančních řádků moc a je-li nutno vytřídit neodpovídající řádky, lze využít funkci ručního výběru řádků pomocí zatržítek zcela vlevo v záhlavích řádků.
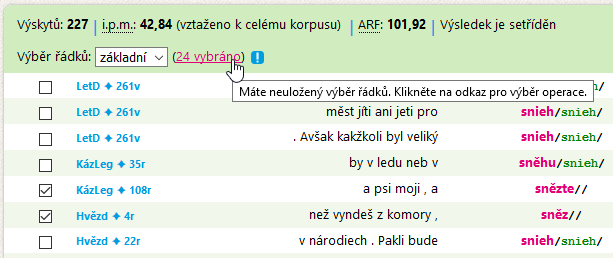
KonText si pamatuje označené řádky i z předchozích stránek konkordance.
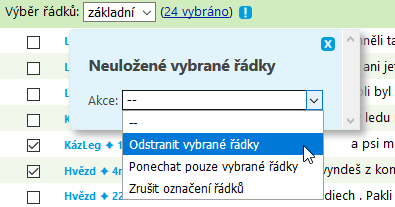
Z konkordance lze odstranit buď označené řádky, anebo neoznačené. V tomto případě (vyřazení tvarů nesouvisejících s lemmatem snieh) je výhodnější označit a vyřadit méně početné řádky se slovesy.
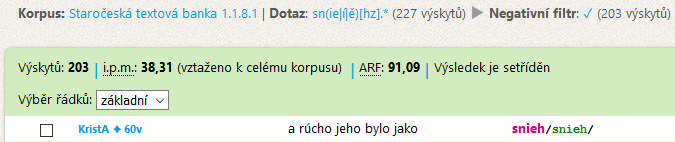
Řádky se z konkordance vyřazují prostřednictvím negativního filtru. Chcete-li se vrátit k původní konkordanci, zvolte v nabídce Konkordance akci Zpět.
Místo prostého výběru řádků pomocí zatržítek lze nalezené výsledky ručně zařazovat do číslovaných skupin. Mezi těmito dvěma režimy (základní a skupiny) se přepíná ve výběru s popiskem Výběr řádků. Stručný popis obou režimů poskytuje dokumentace. Některé pokročilé funkce režimu skupin však mohou vést k tomu, že KonText označení řádků zapomene. Setkáte-li se s tímto problémem, popište nám jej prosím v připomínkách.
Hledání v anotaci slovních tvarů 🔗
V anotaci slovních tvarů (v dodatečných pozičních atributech, např. hyperlemmatech, morfologických značkách, transliteraci) lze vyhledávat pomocí typu dotazu CQL (v jazyce Corpus Query Language), který slouží pro pokročilé hledání (na rozdíl např. od jednoduššího typu dotazu Lemma).
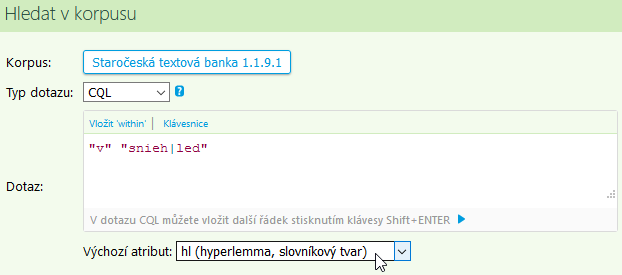
Vystačíme-li si s jedním druhem anotace (tedy s jedním pozičním
atributem), např. pouze s hyperlemmaty, můžeme použít implicitní
formu dotazu. V této zjednodušené podobě dotazovacího jazyka lze
žádaná hyperlemmata zapsat jako regulární výrazy v uvozovkách, např.
"v" "snieh|led"
🔗,
a prohledávaný poziční atribut (hl (hyperlemma, slovníkový tvar))
zvolit jako výchozí (implicitní).
Některé poziční atributy (ze seznamu orámovaného v obrázku červeně) popisuje následující část. Příklady dalších dotazů (z nich některé prohledávají více atributů najednou) naleznete v části Ukázkové dotazy.
Více informací k jazyku CQL naleznete např. v manuálu ČNK a v dokumentaci Sketch Engine.
Dostupná anotace korpusů 🔗
Některé slovní tvary jsou ručně anotované editorem při vzniku edice. Vyhledat a zobrazit lze u nich tuto informaci:
-
komentář ke znění/podobě pramene:
-
obsahem pozičního atributu
komentarmůže být doplněno, torzovité slovo, rekonstruováno, grafika, nebo různočtení: [označení zdroje] (např. Jílek 1955, ESSČ),
-
obsahem pozičního atributu
-
původní zápis tvaru:
-
atribut
transliteracese používá např. u Klaretových slovníků (kvůli nejistému čtení) nebo mj. při transkripci nenáležité jotace u starších textů (více případů uvádí Metodika přípravy a zpracování elektronických edic starších českých textů), -
atribut
emendacese používá v případě (písařské) chyby a obsahuje opět transliterované znění pramene,
-
atribut
-
označení cizojazyčného textu:
-
atribut
jazykje u českého textu prázdný, u ostatních jazyků obsahuje textcizí jazyk,
-
atribut
- základní tvar:
Automaticky doplněná anotace v korpusech od verze 1.1.10.1 zahrnuje:
- možná hyperlemmata a lemmata2,
- dvojí systém morfologických značek3 (obsahujících prakticky stejnou informaci):
-
a přípustné kombinace hyperlemmat a morfologických značek
spojené pomocí podtržítka
(usnadňující při chybějící desambiguaci hledání vybraného
hyperlemmatu s konkrétními vlastnostmi(4)).
-
atribut
hlt(hyperlemma atag) – spojení hyperlemmat s pozičními značkami a -
atribut
hlat(hyperlemma aatag) – spojení hyperlemmat s atributivními značkami.
-
atribut
3 Obě značkové sady jsou popsány v samostatném přehledu a srovnání tagsetů.
Automaticky anotovány jsou prozatím tyto celé slovní druhy: podstatná jména obecná (apelativní substantiva), příslovce, předložky, spojky, částice a citoslovce. V korpusech verze 1.1.10.1 se anotace u sloves týká prozatím pouze 6. slovesné třídy (vzoru kupovati).
2 Automatická korpusová anotace, tj. (hyper)lemmatizace
a morfologické značkování, je nejednoznačná (nedesambiguovaná).
Atributy hl, lemma, tag/atag
a hlt/hlat obsahují všechny přípustné
možnosti (z pokrytých slovních druhů). Možnosti jsou ve všech
atributech spojené svislou čárou: |), ale lze v nich
vyhledávat individuálně (v rámci možností korpusového manažeru).
(4) Například mužské hyperlemma vól
se v základním tvaru vól (který je shodný se čtvrtým pádem)
může vykládat i jako druhý pád množného čísla ženského hyperlemmatu
vóle (s řidší nulovou koncovkou). Kvůli chybějící desambiguaci
by jednoduché hledání podstatného jména vól ve druhém pádě
pomocí CQL dotazu [hl="vól" & atag=".*c2"]
🔗,
(bez uvedení rodu a čísla)
vedlo nesprávně i k nalezení tvarů lemmatu vóle, protože tvar vól
má více analýz (dvě možná hyperlemmata, dva rody, dvě čísla a tři pády)
a hyperlemmata a morfologické značky se vyhodnocují odděleně.
Naopak při hledání pomocí atributu hlat se obě vlastnosti
vyhodnocují najednou. Je však třeba mít na paměti, že korpusový manažer
najednou pracuje i se všemi hodnotami atributu hlat,
přestože jsou odděleny svislou čárou. Vyhledání poslední nechtěné kombinace
vól_k1gMnSc4|vóle_k1gFnPc2
zamezí v dotazu [hlat="vól_[^|]*c2"]
🔗,
použití výrazu [^|]* (namísto .* používaného
výše), který zastupuje nevyjádřenou část značky, ale neumožní už hledání
přes hranici atributu hlat (ve více hodnotách).
Poziční morfologické značky 🔗
Popis tohoto druhu značek – resp. varianty používané při anotaci korpusů historické češtiny – naleznete ve srovnání tagsetů. Více o pozičním tagsetu (používaném např. v korpusech SYN v ČNK) se dozvíte v manuálu ČNK.
Atributivní morfologické značky 🔗
Atributivní morfologické značky vycházejí z tagsetu brněnské (m)ajky, který se používá v českých korpusech ve Sketch Engine. Naše varianta tagsetu je opět popsána formou srovnání tagsetů.
Značky podstatných jmen začínají kódem k1,
pokračují rodem (např. gM pro mužský – bez rozlišení
životnosti), číslem (např. nD pro dvojné) a pádem (např.
c3 pro dativ), dohromady tedy např. k1gMnDc3
🔗
(značce odpovídá mj. tvar dušníkoma).
Značky příslovcí začínají k6 a
případně pokračují stupněm (např. d2 pro komparativ).
Značky předložek mají např. tvar k7c2, když vyžadují genitiv.
Spojky, částice a citoslovce mají jednoduché značky: postupně k8,
k9 a k0. Značky pro interpunkci začínají
atributem kI.
Anotace sloves se připravuje (viz výše). Jejich značky začínají
kódem k5 a rozlišují např. tvary imperfekta (mM)
a aoristu (mO). Příklady celých značek a tvaru od každého
slovního druhu a kategorie naleznete v odkazovaném srovnání tagsetů.
Ukázkové dotazy 🔗
Kromě pokročilých dotazů zde naleznete i přehled dotazů z předchozího textu.
-
-
Tvary zadané regulárním výrazem:
sn(ie|í|ě)[hz].*🔗 (typ dotazu fráze) - Dotaz pokrývá všechny (i nástupnické) tvary lemmatu snieh.
-
Tvary zadané regulárním výrazem:
-
-
Podle slovního druhu:
"N.*"🔗,"[VDRCTI].*"🔗 (typ dotazu CQL; výchozí atribut:tag) -
Zvolte typ dotazu CQL (i v následujících příkladech),
vyberte výchozí atribut tag (poziční morfologická značka) a zadejte dotaz
"N.*"🔗. Ve výsledcích budou převážně (vzhledem k chybějící desambiguaci) tvary podstatných jmen obecných. Ostatní tvary automaticky anotovaných slovních druhů naleznete dotazem"[VDRCTI].*"🔗 (částečně slovesa; úplně příslovce, předložky, spojky, částice a citoslovce).
-
Podle slovního druhu:
-
-
Konkrétní morfologické kategorie:
"k1gMnDc3"🔗 (typ dotazu CQL; výchozí atribut:atag) - Dotaz vyhledá všechna anotovaná substantiva mužského rodu ve třetím pádě dvojného čísla.
-
Konkrétní morfologické kategorie:
-
-
Netriviální předložková skupina:
[tag="R...4.*"] []{0,1} [tag="N...4.*"]🔗 (typ dotazu CQL; výchozí atribut se neuplatňuje) - Dotaz popisuje předložkovou skupinu ve 4. pádě, v níž může být mezi předložkou a podstatným jménem navíc libovolná pozice (např. přídavné jméno nebo zájmeno).
-
Netriviální předložková skupina:
-
-
V lemmatizaci:
"v" "snieh|led"🔗 (typ dotazu CQL; výchozí atribut:hl) -
Dotaz nalezne všechny výskyty tvarů hyperlemmatu (slovníkového
tvaru) v
(čímž by byla pokryta i jeho vokalizovaná varianta ve)
následovaných tvary hyperlemmatu
snieh
nebo led.
Nezapomeňte zvolit typ dotazu CQL a výchozí atribut
hl(hyperlemma).
-
V lemmatizaci:
-
-
Zároveň ve slovním tvaru (transkripci) a emendaci:
[word=".*tě.*" & emendace=".*te.*"]🔗 (typ dotazu CQL; výchozí atribut se neuplatňuje) -
Cílem je najít slovní tvary transkribované s řetězcem
<tě>, ale v prameni chybně zapsané literami
<te>. Jedná se o dvě podmínky na jeden slovní tvar,
takže už je nutné použít nezkrácený zápis dotazu. Ve dvou pozičních
atributech najednou (transkripce:
word, transliterace s chybou písaře:emendace) lze hledat tímto dotazem:[word=".*tě.*" & emendace=".*te.*"]🔗. (Volba výchozí atribut už se v tomto případě neuplatňuje, názvy obou atributů jsou uvedeny explicitně.)
-
Zároveň ve slovním tvaru (transkripci) a emendaci:
-
-
Hledání v ruční anotaci:
[word="pes" & jazyk="cizí jazyk"]🔗,[lemma!="" & tag=""] | [hl!="" & tag=""]🔗 (typ dotazu CQL) - První dotaz vyhledá všechny výrazy pes v cizím jazyce (latinsky) a druhý všechny pozice s lemmaty nebo hyperlemmaty přiřazenými ručně (v elektronických edicích se ručně přiřazují pouze lemmata nebo hyperlemmata, nikoli už morfologické značky).
-
Hledání v ruční anotaci: